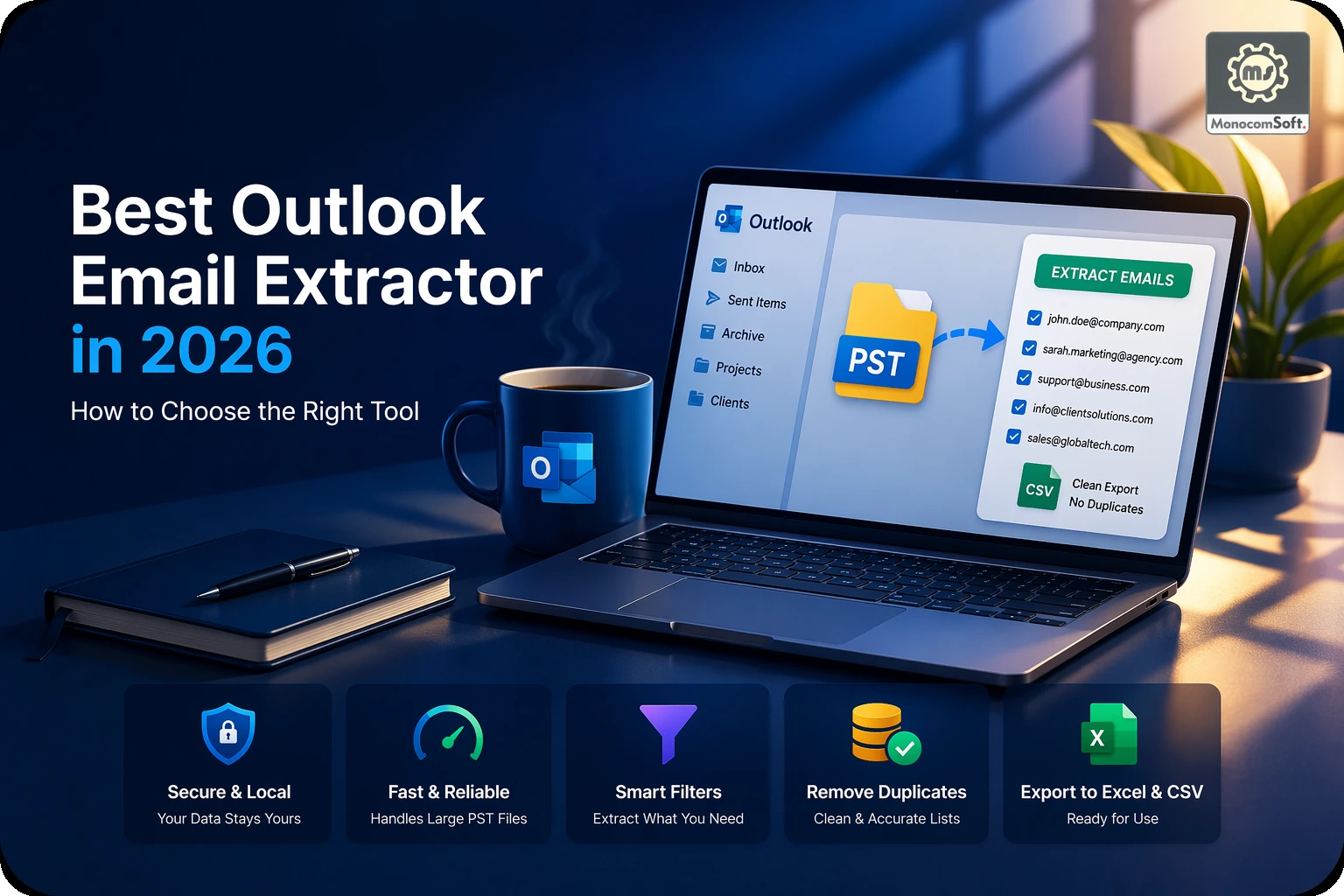
Collecting email addresses sounds easy until you try to do it across real-world files. What starts as a quick copy-paste task can turn into hours of repetitive work when data is spread across PDFs, Excel sheets, Word documents, TXT files, and folders full of mixed content.
That is why this comparison matters. The question is not whether manual copy-paste works at all. The real question is whether it still works well enough once your workload becomes larger, messier, and more repetitive.
Why this comparison matters
Many users do not begin with specialized software. They begin with whatever feels fastest in the moment: open the file, find an address, copy it, paste it into Excel, and repeat.
For tiny tasks, that can be acceptable. But once you need to collect addresses from many sources, maintain cleaner lists, or work on recurring projects, the gap between manual effort and automated extraction becomes very clear.
The reality of manual copy-paste
Manual extraction feels simple because it requires no setup. You can start immediately using files you already have. For a handful of email addresses, this approach is understandable.
Typical manual workflow:
- open one file at a time
- scan the content visually
- copy each email address
- paste it into Excel, CSV, or a text list
- remove obvious repeats by hand
On the surface, it sounds manageable. In practice, it becomes repetitive much faster than most people expect.
Where manual methods break down
1. Time starts disappearing
Even a few hundred entries can consume a surprising amount of time. When email addresses are scattered across multiple pages, tabs, reports, or folders, the work compounds quickly.
2. Errors become hard to avoid
Manual workflows invite mistakes: missed entries, partial selections, accidental spaces, formatting issues, or copied text that is not actually part of the address.
3. Duplicates pile up
The same email address may appear in several files, versions, reports, or exported lists. Removing repeats by hand becomes tedious and inconsistent.
4. Hidden email data gets missed
Email addresses are not always presented cleanly in a neat list. They may be buried inside paragraphs, footers, contact blocks, spreadsheets, notes, or mixed file collections. Manual review often misses these scattered entries.
What automated extraction changes
Automated email extraction changes the workflow from visual searching to structured scanning. Instead of looking for every address yourself, the software scans the selected files or folders, detects email patterns, and gathers them into a usable list.
This usually means the process becomes:
- select source files or folders
- scan automatically
- collect matching email addresses
- remove duplicates
- export into Excel, CSV, or TXT
This shift does more than save time. It also creates a cleaner, more repeatable workflow for future jobs.
A practical comparison
| Factor | Manual Copy-Paste | Automated Extraction |
|---|---|---|
| Speed | Slow and repetitive | Much faster on larger datasets |
| Accuracy | Easy to miss or miscopy entries | More consistent pattern-based collection |
| Duplicate handling | Usually manual | Often automatic |
| Scalability | Poor once file volume increases | Strong for bulk workflows |
| Output structure | Messier and harder to standardize | Cleaner export to usable formats |
| Repeatability | Low | High |
When manual still makes sense
Manual copy-paste is not useless. It can still be fine when:
- you only need a few addresses
- the files are small and clearly formatted
- the task is one-time only
- duplicate cleanup is not a serious concern
In these cases, using a full extraction workflow may be unnecessary. The problem is that many users assume their job is small, only to discover halfway through that it is not.
When automation becomes necessary
Automation becomes the more practical choice when:
- you have many files or folders to scan
- email addresses are scattered across mixed file types
- you need faster turnaround
- you want cleaner export data
- you repeat the same task regularly
- you need duplicate-free lists for downstream use
This is especially common in lead generation, recruiting, internal reporting, CRM preparation, business research, and document-heavy office workflows.
Why most users eventually switch
Most users do not switch because they suddenly want another tool. They switch because the manual process becomes frustrating.
The work takes too long. The lists get messy. The same mistakes repeat. And every new batch of files starts the cycle all over again.
Automation becomes attractive at that point not as a luxury, but as a more practical way to finish the job properly.
Working across PDFs, Word files, spreadsheets, or mixed folders?
Use a file-focused extraction workflow when copy-paste stops being reliable, repeatable, or worth the time.
Final thoughts
Manual copy-paste still works in the strictest sense. But once volume, repetition, and file variety increase, it stops being an efficient method and starts becoming a bottleneck.
Automated email extraction is not simply about speed. It is about creating a cleaner, more accurate, and more sustainable workflow for the kind of data tasks people actually face today.
So what actually works? For very small jobs, manual is still acceptable. For serious, repeatable, or multi-file workflows, automation usually wins by a wide margin.
Frequently Asked Questions
Is manual copy-paste ever good enough for email extraction?
Yes. If you only need a small number of addresses from a simple file, manual copy-paste can still be enough. The issue starts when the data volume grows or the files become more varied and scattered.
Why do manual methods become unreliable at scale?
Because larger workloads create more chances for missed entries, duplicated records, formatting mistakes, and wasted time. The method is workable in small doses, but inefficient for bulk use.
What is the biggest benefit of automated email extraction?
The biggest benefit is practical scalability. Automation helps collect email addresses from many files faster, more consistently, and with less manual cleanup afterward.
Who benefits most from automated extraction tools?
Teams and users handling recurring document-based data workflows usually benefit the most, especially when they need cleaner exports and less repetitive manual effort.