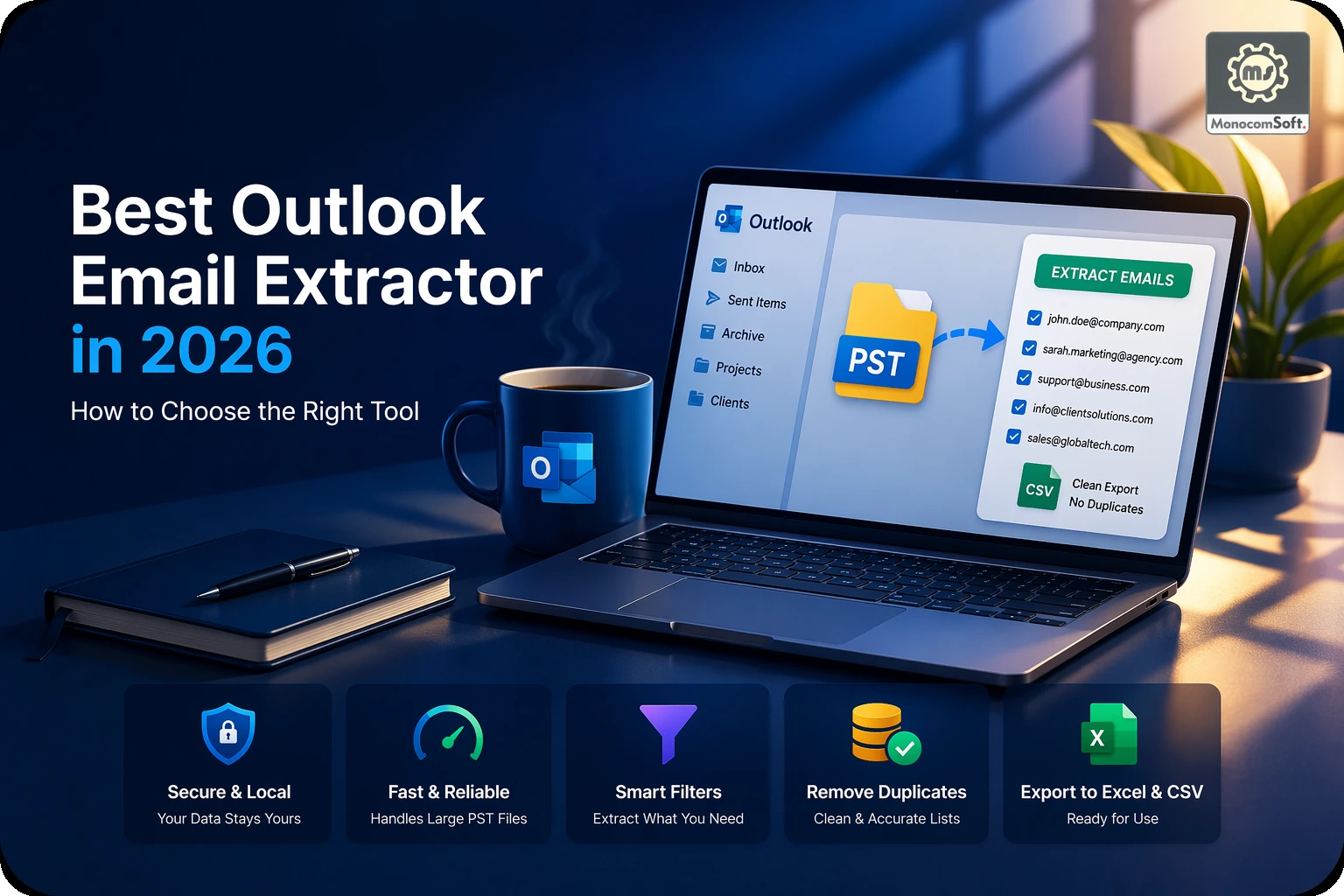
In many businesses, useful contact data is not stored neatly inside one clean CRM or spreadsheet. Instead, it is spread across vendor documents, customer reports, archived folders, Excel files, Word files, PDF records, exported lists, and text-based business documents.
These files often contain valuable email addresses, but not in a format that is ready to use. Before that data can support marketing, CRM updates, outreach preparation, or internal operations, it first has to be found, extracted, cleaned, and structured properly.
What is unstructured file data?
Unstructured file data refers to information that exists inside documents and files without a fixed, database-like format. Unlike a clean contact table where every field has its own place, unstructured data is scattered through paragraphs, tables, notes, footers, resumes, reports, and mixed file collections.
Common examples include:
- PDF reports and brochures
- Word documents and proposals
- Excel sheets with mixed formatting
- CSV exports with inconsistent columns
- TXT files, logs, and archived folders
The data is there, but it is not organized in a way that makes extraction fast or reliable.
Where email data hides in files
Businesses usually do not struggle because they lack contact data. They struggle because the data is buried in too many places. Email addresses may appear inside client records, vendor lists, old correspondence exports, support documents, forms, resumes, quotations, invoices, or project files.
In practical terms, email data often shows up inside:
- customer and supplier documentation
- lead lists collected from different departments
- recruitment files and resumes
- sales reports and old spreadsheets
- archived project folders and document bundles
Why this becomes difficult for businesses
At first glance, collecting emails from files may sound like a simple copy-paste task. But once the number of files grows, the workflow becomes difficult very quickly.
Businesses usually run into problems like:
- too many files spread across different folders
- mixed file formats that require different handling
- duplicate email entries across documents
- missing or incomplete extraction from manual review
- wasted staff time on repetitive collection work
This is where a simple document search task starts turning into an operational bottleneck.
How businesses turn files into usable email lists
Businesses that handle this well usually do not treat it as a random one-off task. They follow a more structured process to make the output useful and repeatable.
1. Gather the relevant file sources
The first step is identifying where the data actually lives. This may include shared folders, archived files, Excel sheets, PDF reports, Word files, exported records, or mixed collections from different teams.
2. Extract the email data
Instead of opening files one by one and copying addresses manually, businesses increasingly rely on software to scan selected files and collect matching email addresses automatically.
3. Clean the extracted results
Raw data is rarely ready to use immediately. Duplicate removal, filtering, and minor cleanup are usually required before the list becomes dependable.
4. Export into a usable structure
Once extracted and cleaned, the results can be exported into a more useful format such as Excel, CSV, or TXT, depending on how the business plans to use the data next.
Why manual methods fail at scale
Manual methods still work when the amount of data is very small. But when businesses deal with large document sets, repeated workflows, or mixed file types, manual collection becomes too slow and too inconsistent.
Teams often underestimate the hidden cost of manual work: not just the time spent copying, but the time spent checking, correcting, de-duplicating, and reformatting the final list.
More importantly, manual review often misses email addresses that are scattered through less obvious areas of documents or buried in larger file collections.
What improves with a structured workflow
Once businesses move from manual collection to a more structured extraction workflow, the benefits are practical and immediate.
- email data becomes easier to centralize
- lists become cleaner and more consistent
- duplicate handling improves
- staff time is used more productively
- future extraction work becomes more repeatable
This shift matters because the goal is not just to "find emails." The goal is to create a usable output that fits real business processes.
Common business use cases
Different teams use file-based email extraction in different ways, but the underlying need is often similar: turn messy contact data into something organized and workable.
- Marketing teams: build usable contact lists from older reports, data dumps, and document collections
- Sales teams: organize scattered lead information gathered from multiple file sources
- HR teams: collect candidate contact data from resumes and application files
- Operations teams: clean internal records and standardize data from exported or archived business files
Why MonocomSoft File Email Extractor is worth considering
If your workflow depends on collecting email addresses from file-based sources rather than live mailboxes, MonocomSoft File Email Extractor is built around that exact requirement.
Key practical advantages include:
- support for multiple file formats and folder-based scanning
- faster extraction from mixed file collections
- clean export into structured formats
- duplicate reduction for more usable lists
- a simpler workflow for repetitive document-based tasks
For users who regularly work with business files rather than just mailbox archives, it is a practical option to evaluate.
Need to turn mixed files into cleaner email lists faster?
Use a file-based workflow that scans one or many documents, reduces duplicates, and exports results into a usable format.
Final thoughts
Unstructured files already contain a large amount of usable business data. The problem is that this data is usually scattered, inconsistent, and difficult to reuse in its original form.
Businesses get better results when they stop treating file-based email collection as a manual cleanup task and start treating it as a structured extraction workflow. That change leads to cleaner lists, less wasted time, and more dependable outputs for real business use.
Frequently Asked Questions
What is unstructured email data?
Unstructured email data refers to email addresses scattered across documents, PDFs, spreadsheets, text files, and other business files without a clean, fixed format.
Why is it difficult to extract emails from files?
Because the addresses may be embedded in mixed layouts, paragraphs, tables, notes, or multiple file types, which makes manual extraction slow and inconsistent.
How do businesses clean extracted email data?
They usually remove duplicates, filter irrelevant results, fix minor formatting issues, and export the cleaned output into structured formats such as Excel or CSV.
What is the main benefit of turning files into usable email lists?
It makes scattered business data easier to reuse for marketing, CRM preparation, reporting, recruiting, and other communication-related workflows.